
There have been several previous blogs comparing Riak to Cassandra. But, in working with customers, we have found that some key differences may not be apparent during a proof of concept (POC) or even in the early days of application development. In this blog, we will provide a brief comparison of Riak and Cassandra and review a few things to consider during a POC.
In the Beginning…
Riak was inspired by the Amazon Dynamo whitepaper (first released in 2007). This paper had a huge impact on readers and spawned the open source NoSQL movement. Cassandra takes concepts from the Amazon Dynamo paper and also relies heavily on the Google Bigtable whitepaper. These foundational architectures have allowed Riak and Cassandra to become the powerhouse NoSQL databases that they are today.
Both Riak and Cassandra provide fast performance, scalability, and high availability. Both can store and manage Terabytes or Petabytes of data. Both scale for millions of concurrent users and can handle more than 250,000 transactions per second with sub-millisecond latency. They are the NoSQL databases used by companies like The Weather Company and Uber.
So, how do you choose the right one for your use case? Let’s review some of the differences.
Data Models
Riak is a key-value store that stores data as a combination of keys and values. With Riak KV, you can store anything you want purely as a key and a value—JSON, XML, HTML, documents, binaries, images, and more. Keys are binary values used to uniquely identify an object. Riak TS is specifically optimized for time series data like IoT sensor data or other time-stamped data. In Riak TS, you store data in tables.
Cassandra is a partitioned row store. With Cassandra, partitioned rows are organized into tables with a primary key. Each key identifies a row and each row has a variable number of elements. This ability to have rows with different elements means you can store many different types of data. Cassandra is often described as a BigTable.
Cassandra works best when your schema is pre-defined. It is best suited for data that can be treated as a collection of properties. Riak KV is best when data is a binary object, opaque blob or JSON. Example use cases for Riak include: storing user and session data, storing chat messages, and storing unstructured content and documents. Riak TS is best for IoT and time series data.
Writing and Reading Data
Riak and Cassandra both provide fast read and write operations and each can be tuned for read-intensive, write-intensive, or mixed workloads. Riak KV is best for read-intensive or mixed workloads. Riak TS is optimized for fast reads and writes of time series data. IoT sensor data can be write-intensive due to the high volume of data and is normally read using range queries. Let’s look at how you read and write data with Riak and Cassandra.
Riak KV provides a REST-ful HTTP API as well as a Protocol Buffers API for basic create, read, update, and delete (CRUD) operations. Riak KV also includes advanced operations such as secondary index searches, text search (via Apache Solr), and MapReduce.
With Riak TS, you use SQL to CREATE TABLEs, INSERT data and SELECT data for queries. You can also use the Riak Spark Connector for integration with Apache Spark. In Riak TS, the primary key defines both the sort order on disk and the time quantum for co-location of data. This makes range queries exceptionally fast. Riak TS also supports storing data as key-value, which may be useful for storing information like sensor metadata.
Cassandra uses CQL, an SQL-like language, to read and write data (the Thrift API has been deprecated). To write data, you create a keyspace and insert data in a table. To read data, you use SELECT statements. You can have both primary and secondary indexes in your tables. Cassandra supports range queries and Cassandra 2.2 introduced JSON support for SELECT and INSERT statements. The JSON keyword can be used to insert a JSON-encoded map as a single row. The format of the JSON map will generally match when returned by a SELECT JSON statement on the same table.
Data Consistency / Data Accuracy
A key premise of the Dynamo paper is that data must be available. Based on the CAP theorem, we know that you can’t have consistency (C), availability (A), and partition tolerance (P), all at the same time. Both Cassandra and Riak are AP systems that provide the ability to tune the consistency and replication factor to match your use case. However, Riak and Cassandra differ in how they resolve data conflicts that occur due to eventual consistency.
Riak KV uses logical clocks, called dotted version vectors (DVVs), to ensure data accuracy. As data is updated, DVVs provide a causal history that makes it possible to determine the precise order of events. If concurrent writes cannot be resolved, DVVs ensure that all writes are stored as siblings. These sibling versions provide information that allows for conflict resolution logic when reading data. DVVs play an important role in minimizing the need for client-side conflict resolution.
Riak also provides the option to use Riak Data Types for fast, automatic server-side conflict resolution in the application. Riak Data Types are convergent replicated data types (CRDTs) and include:
- Counters
- Flags
- HyperLogLogs
- Maps
- Registers
- Sets
Cassandra uses wall clock timestamps to determine which concurrent write to store. This last writer wins (LWW) approach can lead to lost updates. If the system clock goes backward for any reason, Cassandra’s session consistency guarantees may not hold. LWW is a good approach when data is immutable. If your use case requires LWW, Riak can be configured to use it.
Multi-datacenter Replication
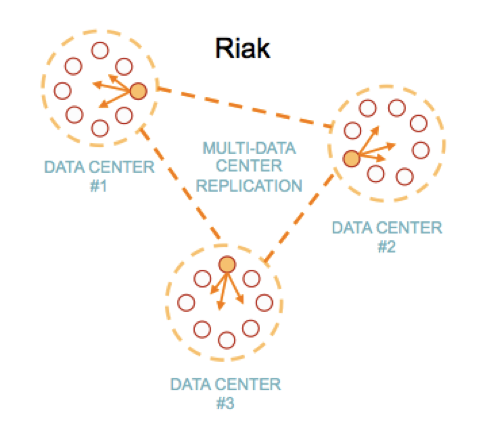 Riak and Cassandra both provide the ability to replicate data across multiple data centers but they each take a different approach. Riak uses multi-cluster replication where each cluster has a separate hash ring. Operators have the ability to manage each cluster and select all or part of the data to replicate across a WAN. In Riak, multi-datacenter replication has two primary modes of operation: full sync and real-time. Data transmission between clusters is optimized for WAN links and can be encrypted via OpenSSL. Riak also allows for per-bucket replication for more granular control.
Riak and Cassandra both provide the ability to replicate data across multiple data centers but they each take a different approach. Riak uses multi-cluster replication where each cluster has a separate hash ring. Operators have the ability to manage each cluster and select all or part of the data to replicate across a WAN. In Riak, multi-datacenter replication has two primary modes of operation: full sync and real-time. Data transmission between clusters is optimized for WAN links and can be encrypted via OpenSSL. Riak also allows for per-bucket replication for more granular control.
Cassandra achieves multi-datacenter replication across WANs by splitting the hash ring across two or more clusters. This requires operators to configure a NetworkTopologyStrategy, Replication Factor, a Replication Placement Strategy, and a Consistency Level for local requests and cross-datacenter requests. It can be quite complex to manage this large ring of nodes across data centers. Your Cassandra rings can grow into hundreds or even thousands of nodes.
Total Cost of Ownership
Both Riak and Cassandra are masterless, highly available databases that persist replicas and handle failure conditions. But the extent to which they automatically handle operations and failure conditions affects their overall cost of ownership.
 Riak is architected for resiliency. In the event of a network partition or hardware failure, Riak continues to operate at scale serving read and write requests. Data is automatically distributed across the remaining nodes.
Riak is architected for resiliency. In the event of a network partition or hardware failure, Riak continues to operate at scale serving read and write requests. Data is automatically distributed across the remaining nodes.
Riak scales easily using commodity hardware. You simply add nodes for near-linear performance increases. Should a node fail, it is easy to replace a node. When nodes are added or replaced, the cluster rebalances automatically (no manual data sharding). Riak resource utilization is optimized and predictable. This ease of scale and node recovery minimizes the ongoing operational costs of Riak. Even the largest Riak deployments don’t require dedicated operations staff.
In contrast, operating Cassandra at scale can be quite complex. Recovering a node in Cassandra involves a multi-phase procedure that uses a complex command syntax and requires manually editing of config files and manually restarting nodes. Data can be significantly unbalanced in the cluster when nodes are recovered.
Cassandra performance can be unpredictable and needs manual tuning. Large deployments of Cassandra normally require full-time dedicated staff to keep clusters operational.
Proof of Concept
There are a number of things to consider when doing your POC.
- How are you going to query your data? Use a data model that best matches your query needs.
- Is your data immutable? Is it time series data? If so, you may want a database specifically optimized for time series data like Riak TS.
- How important are data availability and data accuracy? You may want to include tests for reads and writes at scale and under failure conditions.
- How important is controlling the costs of your deployment? Test the efficiencies of the compute resources. Test the ease of adding and replacing nodes in your cluster. Test the impact of re-configuring and tuning nodes when upgrading software and hardware.
Takeaways
Both Riak and Cassandra provide high availability and scale. During your POC, we believe you will find that Riak has a lower TCO than Cassandra and that Riak ensures your data is always available for reads and writes even in the event of outages. Riak also has extra protection to never lose a write for better data accuracy.
Please Contact us for a tech talk to find out more about Riak.
You can find out more about Riak deployments on our Riak Users page.
Links to other Riak resources:
Dorothy Pults
Product Evangelist
@deepults
