
January 14, 2013
This is the second in a series of blog posts that discusses a high-level overview of the benefits and tradeoffs of Riak versus traditional relational databases. If this is relevant to your projects or applications, register for our “From Relational to Riak” webcast on Thursday, January 24.
One critical factor in deciding which database to use is its operational profile. Many customers today are dealing with rapid data growth, intense peak loads and the imperative to maintain economies of scale across a large platform. For these customers, how the database scales up and what impact that has on operations is a huge factor in business and technical decisions around what technology to use.
The cost of scale is one reason why many of our users and customers have picked Riak over a traditional relational system. From experience, users have discovered that scaling a relational system can be expensive, error-prone and lead to significant and disruptive operations projects. In this blog, we’ll take a look at how a relational database’s sharding approach differs from Riak’s consistent hashing approach and what that means for you as an operator.
Historically, relational databases were commonly found running in production on a single server. If capacity and availability needs require more than a single machine, relational databases address scale using a technique called sharding. Sharding breaks data into logical parts (such as alphabetically, numerically or by geographic region) that can be distributed across multiple machines. A simplified example is below.
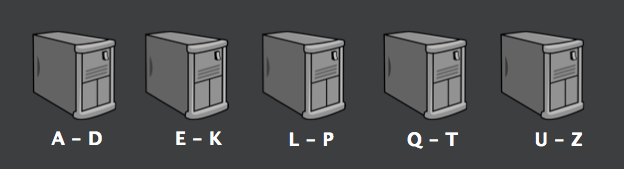
This approach can be problematic for several reasons. First, writing and maintaining sharding logic increases the overhead of operating and developing an application on the database. Significant growth of data or traffic typically means significant, often manual, resharding projects. Determining how to intelligently split the dataset without negatively impacting performance, operations, and development presents a substantial challenge– especially when dealing with “big data”, rapid scale, or peak loads. Further, rapidly growing applications frequently outpace an existing sharding scheme. When the data in a shard grows too large, the shard must again be split. While several “auto”-sharding technologies have emerged in recent years, these methods are often imprecise and manual intervention is standard practice. Finally, sharding can often lead to “hot spots” in the database – physical machines responsible for storing and serving a disproportionately high amount of both data and requests – which can lead to unpredictable latency and degraded performance.
To avoid sharding (and the associated expenses), data in Riak is distributed across nodes using consistent hashing. Consistent hashing ensures data is evenly distributed around the cluster and new nodes can be added with automatic, minimal reshuffling of data. This significantly decreases risky “hot spots” in the database and lowers the operational burden of scaling.
How does consistent hashing work? Riak stores data using a simple key/value scheme. These keys and values are stored in a namespace called a bucket. When you add new key/value pairs to a bucket in Riak, each object’s bucket and key combination is hashed. The resulting value maps onto a 160-bit integer space. You can think of this integer space as a ring used to figure out what data to put on which physical machines.
How? Riak divides the integer space into equally-sized partitions (default is 64). Each partition owns the given range of values on the ring, and is responsible for all buckets and keys that, when hashed, fall into that range. Each partition is managed by a process called a virtual node (or “vnode”). Physical machines in the cluster evenly divide responsibility for vnodes. Each physical machine thus becomes responsible for all keys represented by its vnodes.

When nodes are added or removed, data is rebalanced automatically without any operator intervention. New machines assume ownership of some of the partitions and existing machines hand off relevant partitions and associated data until data ownership is equal amongst nodes. Riak also has an elegant approach to making cluster changes such as adding or removing nodes, allowing you to stage up the changes, view the impact on the cluster, and then choose to commit or abort the changes. Developers and operators don’t have to deal with the underlying complexity of what data lives where as all nodes can serve and route requests. By eliminating the manual requirements of sharding and much of the potential for “hot spots,” Riak provides a much simpler operational scenario for many users that lets them add and remove machines as needed, no matter how much they grow.
Want more info on relational vs Riak approaches? Sign up for the webcast here or read our whitepaper on moving from relational to Riak.
