
If you’ve been fortunate enough to have been studying penguins at McMurdo these last few seasons you may have missed the attention “Time Series” has been getting in the Big Data space. Then again, maybe not. Because if you were doing scientific work whilst snug in your North Face you may have been tracking a colony of fine feathered friends via cute penguin sized solar powered, waterproof arduino backpacks. Maybe you were just recording things like snowfall, snowpack and temperature. I jest, environmental data can be quite… involved. In either case you’ve been recording data over time and – bam – just like that, you’re right in the midst of one of the largest drivers of data oriented applications today: Time Series.
So what’s the big deal? People have been recording temporally oriented data since we could chisel on tablets. Not so new. Well, as it turns out, thanks to the software-eating-the-world thing and the Internet of Things we happen to be amassing vast quantities of all sorts of data that tell us something about almost every facet of our modern lives. Very shiny. The demand for systems that are capable of storing and retrieving temporal data on an ever increasing scale necessitates systems that are specifically designed for this purpose.
You might say, well, there are plenty of solutions that store vast quantities of data. I’d say you’re right, we make one ourselves – Riak KV (Key / Value.) Why do we need something specifically designed for time series data? As it happens, there are two fundamental requirements that make a time series database a time series database – data co-location and efficient range retrieval by arbitrary interval. A system that stores data in a user defined sorted order will make that data available for sequential reads which is partially responsible for the other fundamental requirement of a times series oriented database, namely, efficient range retrieval. Data co-location (storing data in sorted order in the same place) is the most critical consideration because even though many performance driven applications have moved to solid state drives, sequential i/o is still much faster than random i/o even when using SSDs over HDs.
So, how does Riak TS do it?
I often think of Riak as a distributed computing company which applies its core competency in the area of data persistence. Consequently, Riak KV, our flagship distributed database, has been in production at many of the largest organizations in the world for quite some time. A while back I wrote about some of the key architectural principles that make Riak one of the most resilient open source databases available. Riak TS is built on the same core architecture as Riak KV and inherits that architecture’s resilience, fault tolerance, scalability and operational simplicity. Rather than building a completely new code base, Riak TS implements times series specific capabilities at the data distribution and storage layer while leveraging riak_core for its proven resiliency.
Let’s review how data distribution works in Riak KV and contrast that with how data is distributed in Riak TS. Riak is designed to run as a distributed, clustered system out of the box. Sure, you can run a Riak “cluster” consisting of a single physical instance (and that’s actually how I develop against Riak on my personal machine) but a production deployment will always be a cluster of machines. Being a distributed system, much of the magic is in how data is distributed about the cluster. Riak uses the SHA hash as its distribution mechanism and divides the output range of the SHA hash evenly amongst participating nodes in the cluster. Consider the following masterpiece:
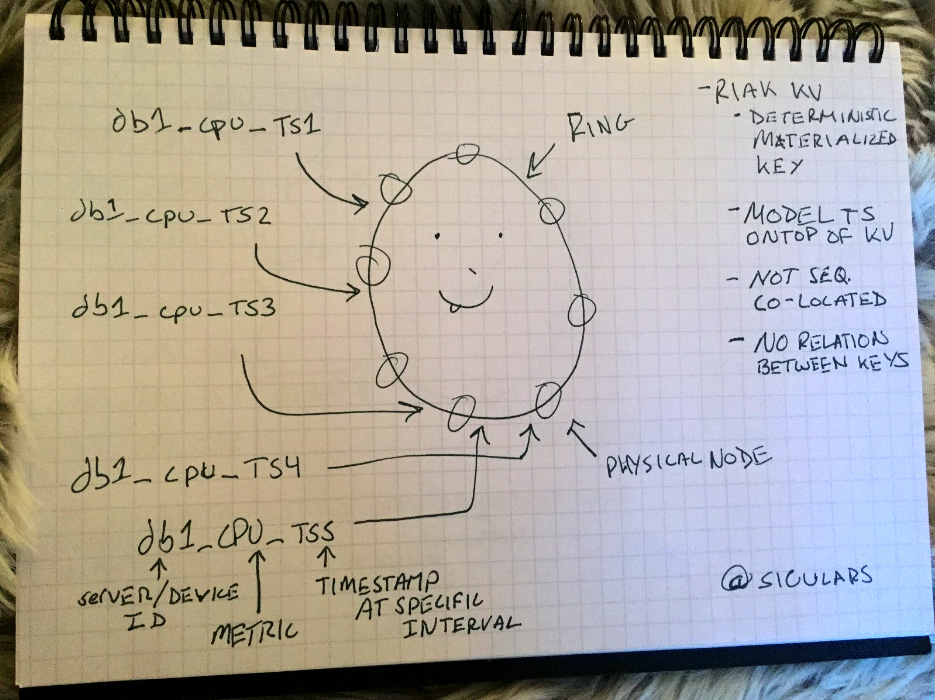
In the Riak KV approach, each key, “db1_cpu_TS{#}”, is a unique object that is hashed and stored in some random section of the ring independently of any other key, regardless of sequence in the timestamp (TS{#} in my masterpiece). This method, often referred to as deterministic materialized keys, has been used very effectively to model a time series data model onto a key value data model. Indeed, this is more or less how folks have deployed time series use cases when using key/value databases such as Riak KV. Nevertheless, when employing this sort of method it is important to note that keys in Riak KV inherently have no relationship to one another.
Now let us consider how Riak TS achieves a higher level of efficiency through data co-locality:
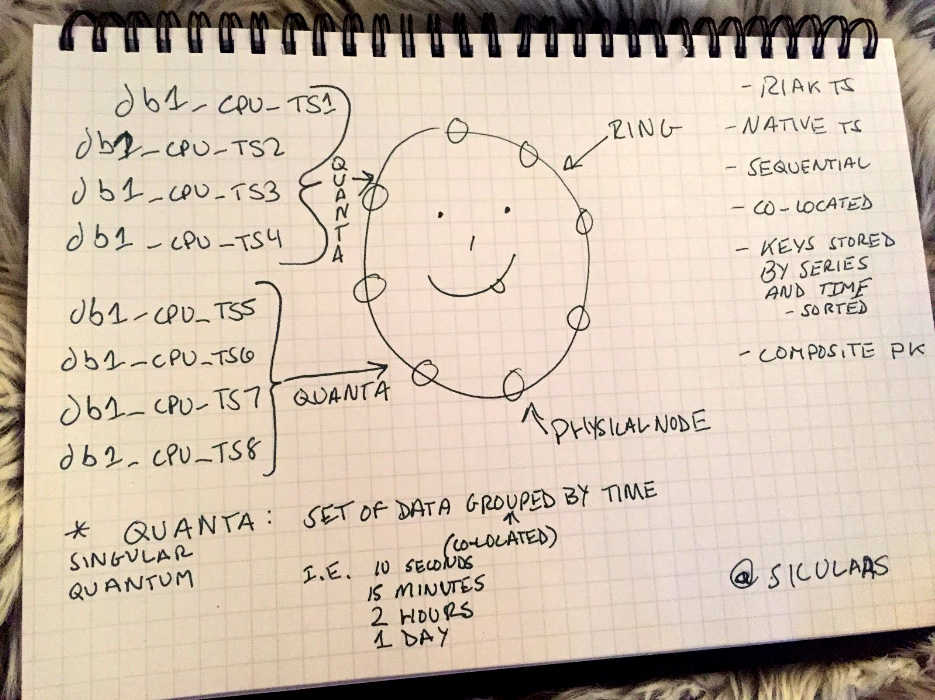
In my second masterpiece we store the same logical keys together internally thereby achieving data co-location. Riak TS is able to group data by user defined time ranges in order to keep data co-located in the same place in the cluster, in the same place on disk, sequentially in user defined sorted order. Riak TS is able to do this by introducing the concept of a quantum. A quantum is a single range of time – be it 10 seconds, 15 minutes or 24 hours – where all data for a particular series whose timestamp falls within that range will be co-located together on disk. Beyond the considerable performance improvements, new features and capabilities, this one architectural tweak is largely responsible for making Riak TS a time series database. Like Riak KV, Riak TS achieves high availability via parallel, asynchronous writes to a configurable number of replicas. Similarly, the same riak_core at the heart of Riak KV facilitates the distributed scalability of Riak TS.
In practice, Riak TS is a departure from the unstructured nature of Riak KV. Riak TS is structured. The developer will create a table schema by executing a CREATE TABLE statement to instruct Riak not only what shape of data to anticipate but also what quantum to implement for each table. Selecting an appropriate quantum for your data will be a crucial consideration. This is generally a function of your ingest frequency in terms of bytes over time in conjunction with your usage pattern. Heavy write patterns favor a smaller quanta to distribute your data across a larger number of nodes (read disks). Heavy read patterns favor larger quanta for a longer sequential read, yet too large a quanta may result in hotspots. Riak TS will divide a query’s requested date range into smaller queries based on the quanta size for the table. Those queries will be executed in parallel (be aware of the max quanta configuration option). For example, a request for data from 12pm to 1pm, stored in a table with a 15 minute quantum, will result in four quanta retrievals.
In addition to a DDL, Riak TS offers a subset of SQL to access time series data. We currently support arithmetic functions and a number of aggregations such as min, max, stddev, avg and count. Features already on the roadmap for future versions include limit, histogram, group by and alter table just to highlight a handful. What’s interesting about Riak TS’s implementation from a data modeling perspective is that instead of only storing a single value at a particular point in time for a particular series, Riak TS has the ability to store multiple typed columns including a varchar column which could be overloaded with stringified json. Any typed column may be used in a WHERE clause and will be executed within the storage layer as a table scan. For more complex analysis Riak TS will connect with Spark via our open source Spark Connector. Spark Connector provides Spark SQL and Dataframes functionality for Riak TS tables, while having RDD-based operations for KV buckets. Developers can use Java, Scala and Python to develop Spark applications with Riak TS.
What’s Next?
Personally, as a developer who’s had to build solutions in this space, I’m very excited to see this product come into its own. It’s been a long time in development and every release has brought better usability, features and performance. I want to thank all the engineers at Riak who’ve worked to make this a reality – everyone from core engineering to the dedicated TS team, LevelDB backend, Client libraries, Performance testing, Services, Documentation and beyond. It was truly a team effort. The teams continue to improve Riak TS at a rapid clip. Riak TS 1.2 brought riak_shell, an interactive repl where you can execute SQL directly against time series tables, enhancements to arithmetic and aggregate functions, RHEL 6/7 and Ubuntu 12.04/14.04 production support. Most notably, Riak TS 1.3 is the first open source release of Riak TS. TS 1.3 brings us Multi-cluster Replication and flexible primary keys relaxes certain primary key constraints among other things, please see the release notes for more information. Our roadmap for future releases includes features like DROP TABLE, ALTER TABLE, ORDER BY, GROUP BY and a number of other functionality enhancements.
I know everyone has their own feature wishlist so download Riak TS and leave a comment, send us some mail and let us know what you’re looking for in upcoming releases. How are you using time series today? Having sat in on product and engineering discussions, I can tell you your comments and feedback directly influence the product roadmap.
