
July 18, 2011
(This was originally posted on Ryan Zezeski’s working blog “Try Try Try“)
In this post I want to give a quick overview of inline fields, a recent addition to Riak Search that allows you to trade-off disk space for a considerable performance bump in query execution and throughput. I’m going to assume the reader is already familiar with Search. In the future I may do a Search overview. If you would like that then ping me on twitter.
The Goal
Recently on the Riak Users Mailing List there was a discussion about improving the performance of Search when executing intersection (i.e. AND) queries where one term has a low frequency and the other has a high frequency. This can pose a problem because Search needs to run through all the results on both sides in order to provide the correct result. Therefore, the query is always bounded by the highest frequency term. This is exasperated further by the fact that Search uses a global index, or in other words partitions the index by term. This effectively means that all results for a particular term are pulled sequentially from one node. This is opposed to a local index, or partitioning by document, which effectively allows you to parallelize the query across all nodes. There are trade-offs for either method and I don’t want to discuss them in this blog post. However, it’s good to keep in mind 1. My goal with this post is to show how you can improve the performance of this type of query with the current version of Search 2.
What’s an “Inline” Field, Anyways?
To properly understand inline fields you need to understand the inverted index data structure 3. As a quick refresher the gist is that the index is a map from words to a list of document reference/weight pairs. For each word 4 the index tells you in which documents it occurs and its “weight” in relation to that document, e.g. how many times it occurs. Search adds a little twist to this data structure by allowing an arbitrary list of properties to be tacked onto each of these pairs. For example, Search tracks the position of each occurrence of a term in a document.
Inline fields allow you to take advantage 5 of this fact and store the terms of a field directly in the inverted index entries 6. Going back to my hypothetical query you could mark the field with the frequently occurring term as inline and change the AND query to a query and a filter. A filter is simply an extra argument to the Search API that uses the same syntax as a regular query but makes use of the inline field. This has the potential to drop your latency dramatically as you avoid pulling the massive posting 7 altogether.
WARNING: Inline fields are not free! Think carefully about what I just described and you’ll realize that this list of inline terms will be added to every single posting for that index. If your field contains many terms or you have many inline fields this could become costly in terms of disk space. As always, benchmarking with real hardware on a real production data set is recommended.
The Corpus
I’ll be using a set of ~63K tweets that occurred in reaction to the the devastating earthquake that took place in Haiti during January of 2010. The reason I choose this data-set is because it’s guaranteed to have frequently occurring terms such as “earthquake” but also has low occurring terms 7 such as the time the tweets were created.
The Rig
All benchmarks were run on a 2GHz i7 MBP with an SSD 8. An initial run is performed to prime all systems. Essentially, everything should be coming from FS cache meaning I’ll mostly be testing processing time. My guess is disk I/O would only amplify the results. I’ll be using Riak Bench and running it on the same machine as my cluster. My cluster consists of four Riak nodes (obviously, on the same machine) which I built from master 9.
If you’d like to run the benchmarks on your own hardware please see the RUN_BENCHMARKS.md file.
Naive Query
"text:earthquake"
The naive query asks for every document id 10 that includes the word earthquake. This should return 62805 results every time.
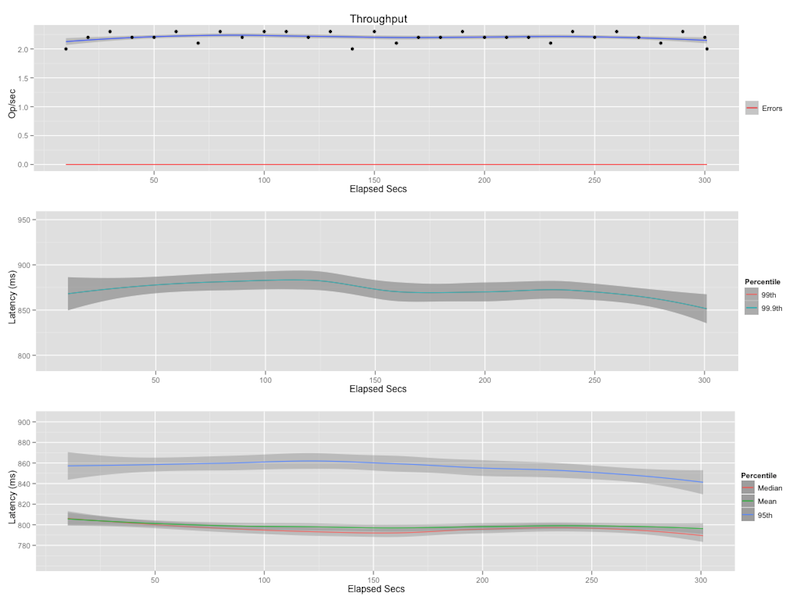
Scoped Query
"text:earthquake AND created_at:[20100113T032200 TO 20100113T032500]"
The scoped query still searches for all documents with the term earthquake but restricts this set further to only those that were created in the provided three minute time span.
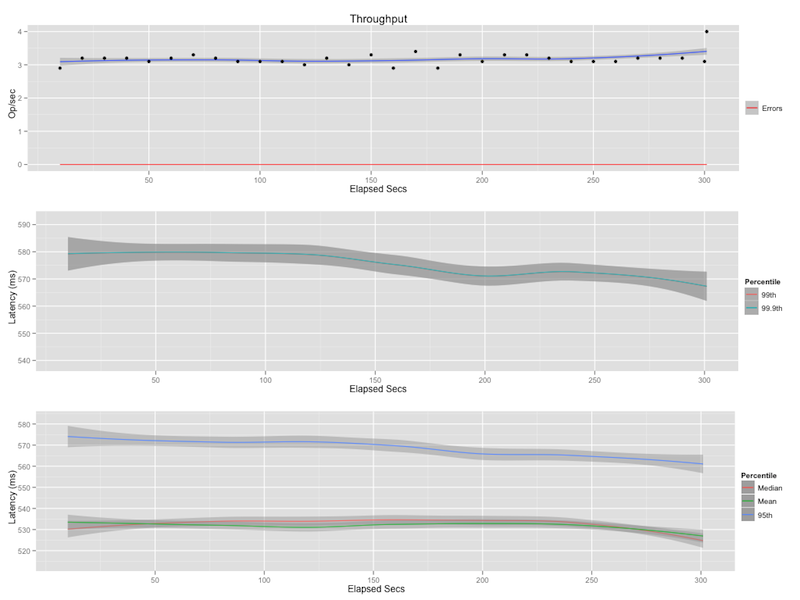
Scoped Query With Filtering
"created_at:[20100113T032200 TO 20100113T032500]" "text:earthquake"
This is the same as the scoped query except earthquake is now a filter, not a query. Notice, unlike the previous two queries, there are two strings. The first is the query the second is the filter. You could read that in English as:
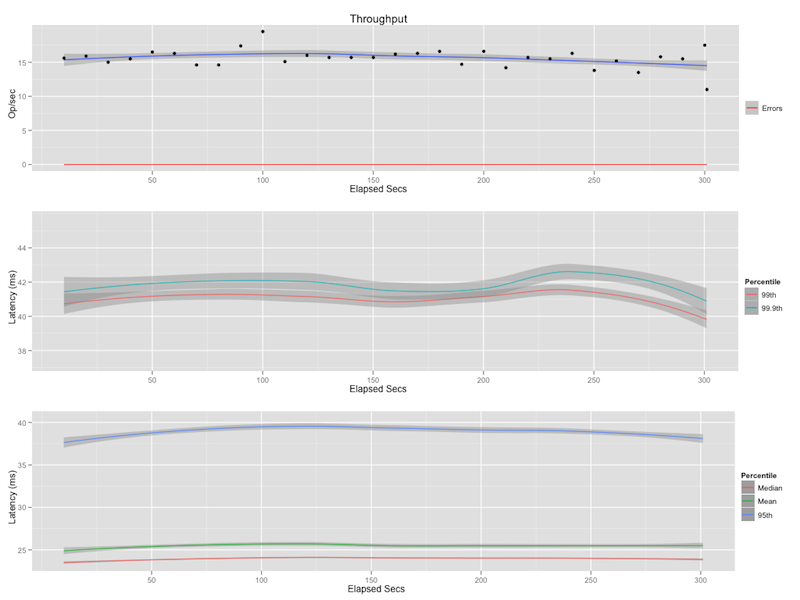
Wait One Second!
Just before I was about to consider this post wrapped up I realized my comparison of inline vs. non-inline wasn’t quite fair. As currently implemented, when returning postings the inline field’s value is included. I’m not sure if this is of any practical use outside the filtering mechanism but this means that in the case of the naive and scoped queries the cluster is taking an additional disk and network hit by carrying all that extra baggage. A more fair comparison would be to run the naive and scoped queries with no inline fields. I adjusted my scripts and did just that.
Naive With No Inlining
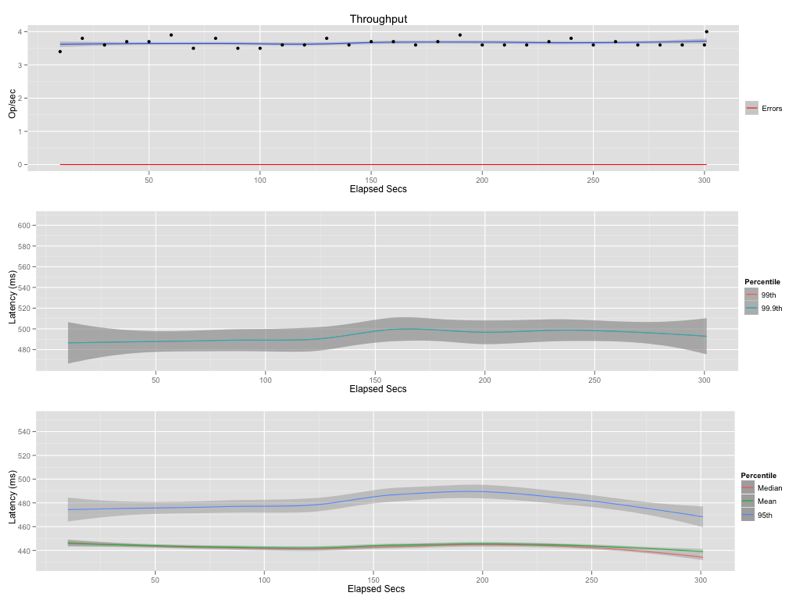
Scoped With No Inlining
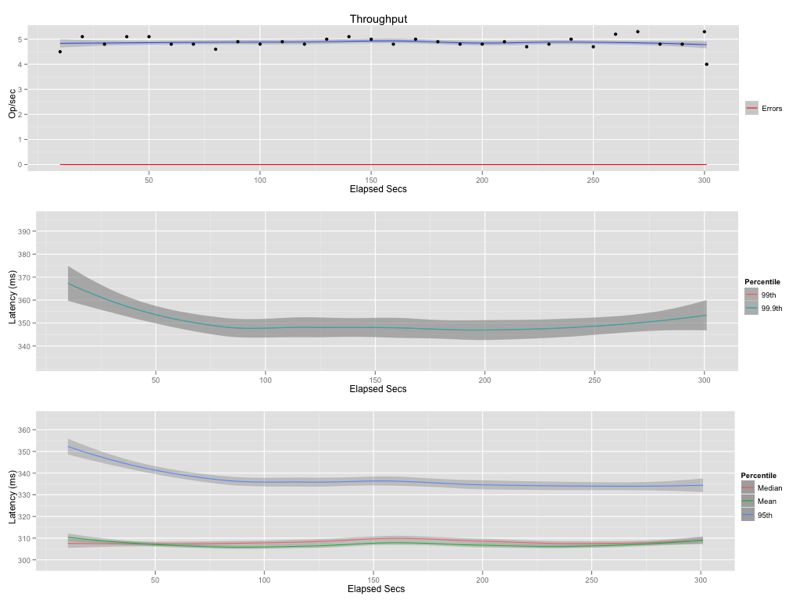
Conclusions
In this first table I summarize the absolute values for throughput, 99.9th percentile and average latencies.
| Stat | Naive (I) | Naive | Scoped (I) | Scoped | Scoped Filter |
|---|---|---|---|---|---|
| Thru (op/s) | 2.5 | 3.5 | 3 | 5 | 15 |
| 99.9% (ms) | 875 | 490 | 575 | 350 | 42 |
| Avg (ms) | 800 | 440 | 530 | 310 | 25 |
In this benchmark I don’t care so much about the absolute numbers as I do how they relate to each other. In the following table I show the performance increase of using the scoped filter query versus the other queries. For example, the scoped filter query has three times the throughput and returns in 1/12th of the time, on average, as compared to the scoped query. That is, even its closest competitor has a latency profile that is an order of magnitude worse. You may find it odd that I included the naive queries in this comparison but I wanted to show just how great the difference can be when you don’t limit your result set. Making a similar table comparing naive vs. scoped might be useful as well but I leave it as an exercise to the reader.
| Stat | Naive (I) | Naive | Scoped (I) | Scoped |
|---|---|---|---|---|
| Thru | 6x | 4x | 5x | 3x |
| 99.9% | 20x | 11x | 13x | 8x |
| Avg | 32x | 17x | 21x | 12x |
In conclusion I’ve done a drive-by benchmark showing that there are potentially great gains to be had by making use of inline fields. I say “potentially” because inline fields are not free and you should take the time to understand your data-set and analyze what trade-offs you might be making by using this feature. In my example I’m inlining the text field of a twitter stream so it would be useful to gather some statistics such as what are the average number of terms per tweet and what is the average size of each term? Armed with that info you then might determine how many tweets you plan to store, how many results a typical query will match and how much extra I/O overhead that inline field is going to add. Finally, run your own benchmarks on your own hardware with real data while profiling your system’s I/O, CPU, and memory usage. Doing anything else is just pissing in the wind.
References
1: If you’d like to know more you could start by reading Distributed Query Processing Using Partitioned Inverted Files.
2: Inline fields were added in 14.2, but my benchmarks were run against master.
3: I like the introduction in Effect of Inverted Index Partitioning Schemes on Performance of Query Processing in Parallel Text Retrieval Systems.
4: In search parlance a word is called a term and the entire list of terms is called the vocabulary.
5: Or abuse, depending on your disposition.
6: Entries in an inverted index are also called postings by some people.
7: Or high cardinality, depending on how you want to look at it.
8: Just like when dynoing a car it’s constant conditions and relative improvement that matter. Once you’re out of the shop those absolute numbers don’t mean much.
9: The exact commit is 3cd22741bed9b198dc52e4ddda43579266a85017.
10: BTW, in this case “document” is a Riak object indexed by the Search Pre-commit hook.
