
I spend a lot of time as a solution architect at Riak talking through use cases and best practices around distributed architectures. One question that comes up often about Riak is “what are the best types of use cases for Riak”. While we’ve traditionally been more focused on real-time applications, with our recent Spark connector work, we now have a great option for both stream and batch processing. To illustrate how you might take advantage of this in an event sourcing use case, let’s take a look at the following architecture.
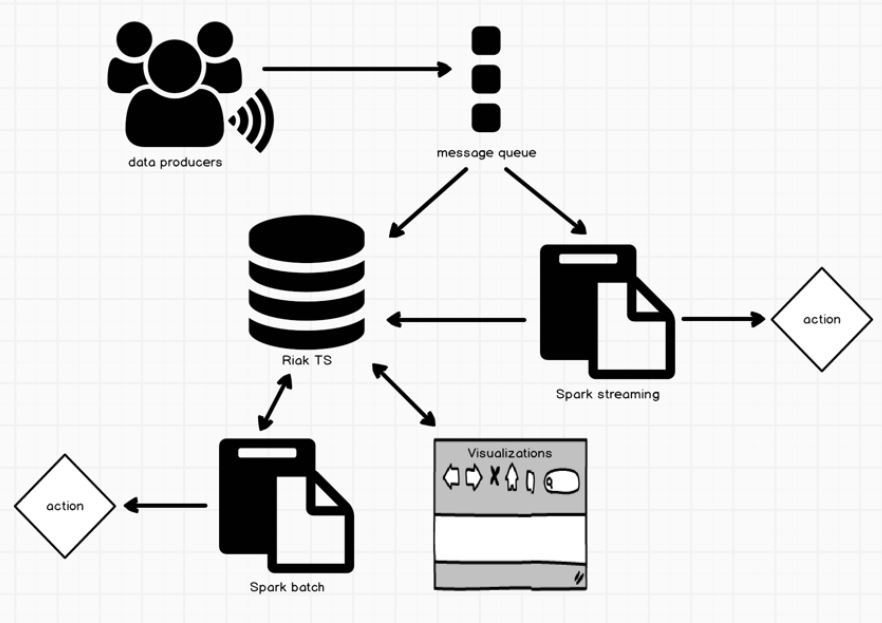
What I’d like to show here, is that for event pattern detection and correlation, there can be a need for both streaming and batch capabilities. Let’s walk through the different parts of the diagram. While Riak TS is well suited for high-velocity data ingestion, a popular architectural approach is to decouple the producers from the data consumers, giving you the flexibility to easily add more consumers as app/service requirements expand. Kafka, a distributed message broker, is a common choice here for its resiliency and ability to handle a high amount of throughput – we’ve recently published an example ingest micro service for Riak TS if you’d like an example to kick start your own efforts.
For the initial (near) real-time processing of events, you can leverage Apache Spark’s streaming capability, which provides a great cluster computation framework that allows you to analyze and correlate data over a sliding window of time, aggregate, transform/augment, or initiate some action (like creating a notification or updating a user record for example). There are other tools you could pick for this piece, like Storm or Samza, but given Riak TS has Spark integration already, it’s likely the obvious choice here. But once you’ve completed the initial processing, you may need to look for correlations across a larger time period or aggregate of events. It’s also a common need to serve up visualizations with varying granularity or perform predictive analytics. This is where Riak TS comes in (as a distributed, persistent datastore optimized for time series data).
Event data is time series data, and there are a few typical types of workloads you can expect post ingestion that your persistent data store should support, be it batch reads for bulk processing, real-time analysis of data across differing spans of time, or read heavy visualizations. In addition to the fault tolerance and availability qualities Riak TS brings, it’s well suited for these types of workloads. Given that eventing systems can generate a large amount of data, choosing a horizontally scaling solution is also key.
Two main capabilities provided by Riak TS give flexibility in these scenarios. Firstly, we control data co-location via the data model, which optimizes for real-time range queries available through a SQL interface. Even though Riak distributes data across potentially a large number of nodes, you have the ability to control how data is partitioned and sorted, optimizing based on the queries you need to run. In a typical Dynamo-based system, it’s possible you’d need to contact a large portion of your nodes to stitch together a result set. Using a composite key in Riak TS, you can ensure data co-location, so reads come from a single node regardless of the cluster size. This means even at scale, you can have performant reads, to drive your visualization layer for example.
Secondly, we’ve recently done some performance work around bulk loading of data, specifically for our Spark connector. Previously, 2i would calculate the covering set of nodes in the cluster, and retrieve the data one vnode at a time. This has now been optimized so that data is extracted in parallel from a computed number of nodes, allowing you to quickly load massive amounts of data. This process requires the Riak client to first request a coverage plan from a single node. Once returned, the client then has the list of nodes (and their corresponding data partitions), which it can now use to make multiple concurrent requests for.
As a solution architect, I’m really excited about the use cases these capabilities can enable. In case you missed the recent announcement, as of 1.3 we’ve officially open sourced Riak TS, and are rapidly iterating on 1.4 which brings, among other things, some SQL richness (group by/order by) and cluster wide expiry. Our community helps us drive our product roadmap, so as always, we’d love to hear about your time series use cases. Test your IoT Time Series IQ and take our Quiz. If you’d like to learn more about Riak TS and our Apache Spark Connector, my colleague Susan Lee has recorded a video demonstration which is available in our video playlist. If you’d like to view a tutorial on using Riak TS with Apache Spark our friends at Databricks are hosting a Notebook on their site.
Feel free to reach out to me via twitter or email if you have further questions.
Tom Sigler
Solutions Architect
@Tom_Sigler
